Multi Tier Architectures for Database Connectivity
Marc A. Mnich
JavaExchange.com
Jan 5, 1998
Copyright ©
1998
| Background: |
The World Wide Web's initial success was largely founded on static HTML data stored in hierarchical file systems. The data was simple to present via the Markup Language and even easier to manage in the shallow structures of the file system.
Today, all that is changing. The recent trend has been to a greater level of complexity in the structure of the Web's data. This complexity has been facilitated by the relational database. From the tracking of "hits" to the implementation of full scale global applications, the database is rapidly becoming a requirement for any site that wishes to be taken seriously on the Web.
The merging of the two technologies (the Web and the relational database) has been slow and the technical approaches as varied as the number of companies providing solutions. Behind all the advertising and hype, however, lies the essential challenge: getting data from the database to the browser and from the browser to the database.
This paper addresses the technical issues of database connectivity with an emphasis on multithreaded languages, e.g. Java and specifically Java Servlets. The context of multithreaded languages was chosen to exemplify the basic concepts as well as to demonstrate the most recent and significant developments in the emerging technologies.
| The Problem: |
The overhead time for establishing a database connection is typically around 1 to 3 seconds. This is the time it takes to locate the database server, establish a communication channel with it, exchange information including username and password, and login. For Web Applications where the database query times are large, this overhead is a small fraction of the overall turn-around-time and generally not a critical issue. More frequently, however, a Web Application is designed to perform numerous short term queries -- queries that retrieve stored HTML text, handle HTML form data, or create HTML text "on the fly" from data stored in a database. For these applications, the database connect time can become the dominant factor in its usability.
It is critical that the database connection time is reduced to a minimum. It should also be noted that the significance of this single issue will grow with the typical user's Internet access bandwidth.
In addition to the timing issue, there is the problem of concurrency commonly encountered when using threaded servlets and database connections. A database statement must have exclusive use of a connection for it to be reliable. This implies that all uses of database connections be thread safe to prevent lock ups and collisions.
[A common mistake is to create a single connection in the initialization section (run only once) of a servlet to be reused for each invocation of the servlet, avoiding the startup timing requirement. While there is nothing to prevent this from being implemented and it usually functions for a single user, it will wreak havoc once placed under a load where concurrent "hits" cause two or more threads to run at the same time. ]
| The Solution: |
A simple solution to the connection timing problem is to create a pool of persistent (reusable) connections to be used by the application components as needed. The pool of connections is created and managed by a separate process or thread commonly called a connection broker. An application component (servlet) sends a request for a connection to the connection broker which services the request. In addition, the broker manages the pool of connections, watches for locked or corrupted connections, logs events and performs other housekeeping tasks. Once the application component has completed its database request, the connection is returned to the pool for reuse.
The design and implementation of a connection broker involves several important challenges. The first, and perhaps most important challenge, is the sharing of a connection's context between broker and application. When a database connection is created, it has a context associated with it that includes various attributes (Id, status, meta data, etc.) which must be kept with the connection if it is to persist across calls. The structure containing this context must be stored in a location accessible to both application and broker or it must be passed between them as needed. The problem of sharing or passing data is much more severe between processes than between threads.
Another consideration in the design of a broker is the extent of housekeeping. A list of questions to be considered for the housekeeping tasks might include the following:
These challenges are handled differently by two fundamental types of broker implementations which are summarized below:
| 3 Tier Architecture: |
| 2 Tier Architecture: |

|
3 Tier Architecture:
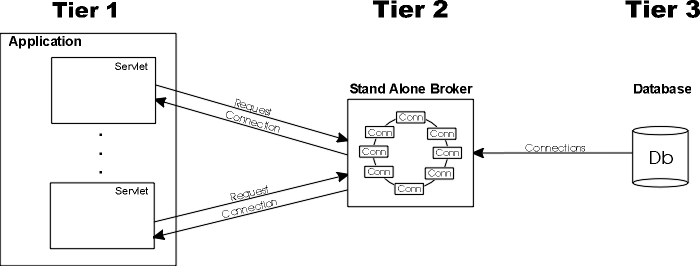
The Tiers, or layers, in a 3 Tier architecture are the Application layer, the Broker layer, and the Database layer (see diagram below). In a complete system for a Web application, there is an additional tier which is typically represented by the client browser. It is possible (and becoming more common) to design a system including both servlets and applets both of which communicate with a common set of databases. These 4 basic layers (browser, server, broker, database) are often used in various combinations when describing 2 and 3 tier architectures leading to confusion about what constitutes a tier. Since this paper's emphasis is on servlet based applications, the browser layer is not included in the tier descriptions.
The application layer (Tier 1) is typically made up of a group of application components (servlets) each of which exchanges information with a database. The middle layer (Tier 2) is a stand-alone server which creates and manages a pool of database connections -- the connection broker. The database layer (Tier 3) is comprised of one or more database instances. Upon system startup, the stand-alone broker creates the requested number of database connections and begins the housekeeping tasks which it continues to run as long as the system is running. Requests for connections are issued from the application servlet threads as the they are "hit" from the browser. Each servlet thread requests a connection and then hands the connection back to the broker for replacement in the connection pool.
As mentioned earlier, the heavy duty context switching between the application processes and the broker process poses a significant problem for the 3 Tier architecture.
[A variation to this basic design (usually called a database proxy sever) exchanges SQL text and query result strings instead of connections. This is an inferior architecture and is rarely used since the introduction of threaded languages and threaded Web server platforms.]
2 Tier Architecture:
In the 2 Tier architecture, the single monolithic broker is replaced by a distributed set of internal broker threads (see diagram). Each servlet contains one or more broker threads, each of which is configurable for number of connections, database instance, housekeeping characteristics, etc.
Upon initialization, each servlet starts up its set of broker threads and keeps them running as long as the servlet is running. Since the brokers are running in their own threads, they continue to run in the background handling connections and performing the housekeeping tasks while the core of the servlet is called in successive threads. If a particular servlet fails, only its own connections are affected allowing the rest of the application to continue running normally.
| Advantages of the 2 Tier Architecture: |
As summarized in the diagram below, there are several important advantages in the 2 Tier approach.
Simplicity also shows itself reflected in cost. It is not uncommon to find 3 Tier solutions costing upwards of $2,000.00 and consisting of thousands of lines of code. Most 2 Tier brokers are freely available with various degrees of housekeeping and can be written for specialized situations with relatively few lines of code.
The distributed broker design allows for great flexibility in dealing with multiple, heterogeneous database instances; the decision making process for connection allocations is simple and natural. In a monolithic broker, the same functionality is either absent or obtained through complex algorithms and non-intuitive parameter settings.
In a 3 Tier system, the equivalent granularity of connection allocation is typically absent or implemented through complex algorithms. Load balancing is typically limited to CPU usage or network traffic alone.
Because broker threads can be scaled and distributed freely, the designer of an application has enormous flexibility in shaping the system to handle new and complex situations.